Amazon Elastic Block Store(EBS)
- EBS 볼륨은 EC2인스턴스의 스토리지 단위로 사용될 수 있다.
- AWS에서 실행 중인 인스턴스에 디스크 공간이 필요할 때마다 EBS 볼륨을 생각하면 된다.
- 이러한 볼륨은 하드 디스크 또는 SSD 디바이스가 될 수 있다.
- 사용한 만큼만 지불할 수 있고 볼륨이 더 이상 필요하지 않게 되면 언제라도 삭제하여 요금을 지불하지 않을 수 있다.
- EBS볼륨은 안정성과 가용성을 목표로 설계된다.
볼륨에 있는 데이터는 가용 영역에서 실행 중인 여러 서버에 자동으로 복제된다. - EBS 볼륨과 하드 디스크 또는 SSD 등과 같은 물리적 미디어 디바이스를 비교했지만, EBS 볼륨이 블록 수준 복제 덕분에 더욱 안정적이다.
- EBS 볼륨 생성 시 요구 사항에 가장 적합한 스토리지 유형을 선택할 수 있다.
성능 및 요금 요구 사항을 기반으로 마그네틱 또는 SSD 중에서 선택할 수 있다. - 적절한 작업에 맞춰 적절한 도구를 선택하는 것이 중요하다.
ex) 데이터베이스 인스턴스를 실행 중인 경우 데이터에 대한 보조 볼륨으로 사용할 데이터베이스를 구성할 수 있다. 이는 운영 체제에 할당된 볼륨보다 빠른 성능을 발휘할 수 있다.
또는 로그용으로 마그네틱 볼륨을 할당할 수도 있다. 마그네틱이 훨씬 저렴하기 때문이다. - Amazon EBS는 보다 높은 수준의 데이터 내구성을 제공하기 위해 볼륨의 특정 시점을 스냅샷을 생성하는 기능을 제공하며 AWS를 사용하면 언제든지 스냅샷에서 새 볼륨을 다시 생성할 수 있다.
- 개선된 재해 복구 보호를 위해 스냅샷을 공유하거나 다른 AWS 리전으로 스냅샷을 복사한다.
ex) 스냅샷을 암호화하고 버지니아에서 도쿄까지 공유할 수 있다. - 추가 비용 없이 EBS 볼륨을 암호화할 수 있다. 암호화는 EC2 측에서 이루어진다.
따라서 EC2 인스턴스와 AWS 데이터 센터 내부의 EBS 볼륨 간에 이동하는 데이터는 전송 중에 암호화된다. - 회사가 성장함에 따라 EBS 볼륨에 저장되는 데이터의 양도 늘어날 것이다. EBS 볼륨은 용량을 늘리고 다른 유형으로 변경할 수 있으므로 하드 디스크에서 SSD로 변경할 수 있다.
ex) 50GB 볼륨에서 16TB 볼륨으로 변경할 수 있다. - 인스턴스를 종료할 필요 없이 즉시 이 크기 조정 작업을 수행할 수 있다.
EBS Volume 시연
EC2 Management Console에서 EC2 인스턴스와 EBS볼륨은 EC2 콘솔에 존재한다.
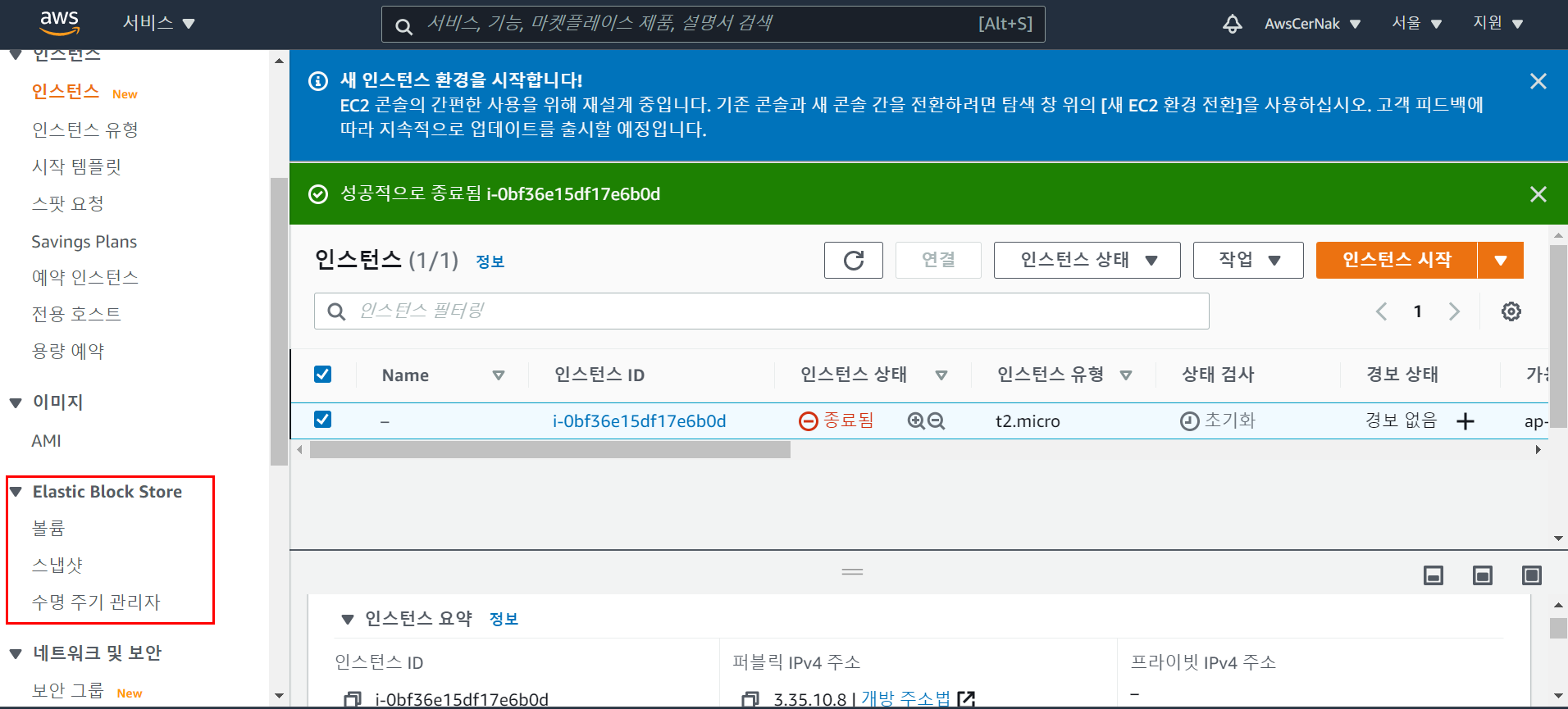
- 인스턴스를 클릭하면 현재 실행중인 인스턴스, 대기중인 인스턴스 등을 볼 수 있다.
- 볼륨은 위의 빨간 박스의 볼륨 사이드바에 위치한다.
- 새 볼륨을 생성하고 이 새 볼륨을 인스턴스에 연결할 수 있다.
- EBS 볼륨을 인스턴스가 상주하는 곳과 동일한 가용 영역에 생성해야 한다.

- 따라서 볼륨을 생성할 때 인스턴스가 ap-northease-2c에 있다면 볼륨도 동일한 가용영역에 생성해야 한다.

- 여기에 볼륨 유형을 마그네틱 또는 SSD와 같이 볼륨을 지정하는 옵션으로 선택할 수 있다.
- 범용 SSD는 GB크기에 대해서만 요금이 청구된다.
- 25GB 볼륨을 생성하고자 하는 경우 크기에 25GB를 지정하면 된다.
- 만약 스냅샷이 존재한다면 스냅샷 ID를 선택하여 복원할 수 있다.
그 후 Attach Volume 버튼을 클릭하여 연결할 인스턴스를 지정할 수 있다.
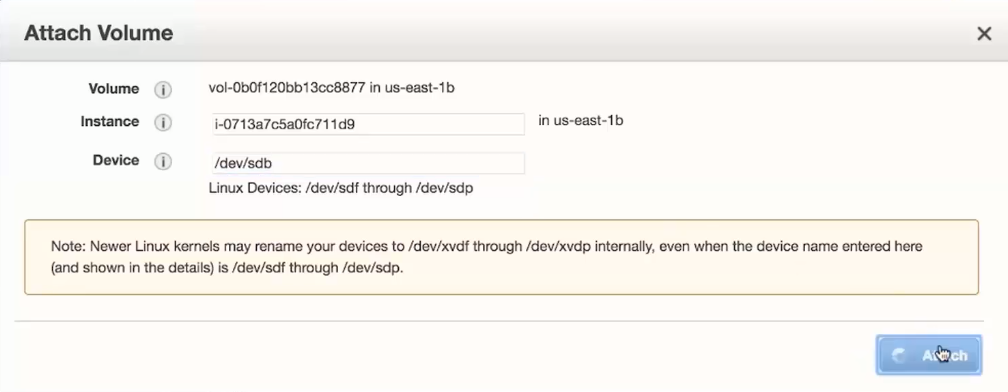
- EBS 볼륨을 생성하고, EC2인스턴스에 연결하고, 형식을 지정하는 것이 얼마나 쉬운지 알 수 있다.
- 볼륨연결을 인스턴스와 해제하더라도 사용가능(available)이라고 표기괸다.
- 현재 인스턴스와 연결되어 있다면 사용중(in-use)이라고 표기된다.
- 언제든 같은 가용영역에 존재하는 인스턴스와 연결하고 해제할 수 있다.
- 볼륨에 태그도 지정할 수 있다. 데이터베이스에서 이 볼륨을 사용 중인 경우 데이터베이스 볼륨이라는 태그 값을 지정할 수 있다.
- 태그가 매우 중요한 이유는 AWS 리소스에 태그를 지정할 경우 태그 기준으로 비용을 분석할 수 있기 때문이다.
즉, 태그 키 이름과 태그 값 데이터베이스 볼륨이 포함된 모든 볼륨에서 특정 시간 동안 얼마나 비용이 발생하는지 알 수 있다. - 같은 방법으로 EC2 인스턴스, EBS 스냅샷, 그리고 태그를 지원하는 모든 것의 비용을 알 수 있다.
Amazon Simple Storage Service(S3)
- 데이터를 저장하고 검색할 수 있는 간단한 API를 제공하는 완전 관리형 스토리지 서비스이다.
즉, Amazon S3에 저장하는 데이터는 특정 서버와 관련이 없으므로 사용자가 인프라를 직접 관리할 필요가 없다.
- Amazon S3 객체를 원하는 만큼 추가할 수 있다.
- Amazon S3는 수조 개의 객체를 보유하면서 초당 최대 수백만 개의 요청을 처리한다.
- 객체는 이미지, 동영상 또는 서버 로그와 같은 거의 모든 데이터 파일이 될 수 있다.
- Amazon S3는 최대 몇 테라바이트 크기의 객체를 지원하므로, 데이터베이스 스냅샷까지도 객체로 저장할 수 있다.
- Amazon S3는 HTTP 또는 HTTPS를 통해 인터넷에서 데이터에 대한 지연시간이 짧은 액세스를 제공하므로 언제 어디서나 데이터를 검색할 수 있다.
- 또한 가상 사설 클라우드 엔드포인트를 통해 Amazon S3에 비공개적으로 액세스할 수 있다.
- Identity and Access Management 정책, S3 버킷 정책 및 객체별 액세스 제어 목록을 사용하여 데이터에 액세스할 수 있는 사용자를 세밀하게 제어할 수 있다.
- 기본적으로 사용자 데이터는 공개적으로 공유될 수 없다.
- 또한 전송 중인 데이터를 암호화하고 객체에서 서버 측 암호화를 사용하도록 지정할 수 있다.
동영상 파일을 가져온다고 가정해 보자
1. 먼저 파일을 저장할 위치가 필요하다.
2. Amazon S3에서 데이터를 보관할 버킷을 생성할 수 있다.
3. 해당 동영상을 버킷에 객체로 추가하기 위해서는 키를 지정해야 한다.
4. 해당 키는 나중에 객체를 검색할 때 사용할 수 있는 문자열이다.
일반적인 방법은 파일 경로와 유사한 방식으로 문자열을 설정하는 것이다.
동영상을 해당 키가 포함된 객체로 Amazon S3에 저장해보겠다.
- 5. Amazon S3에 버킷을 생성하면 해당 버킷은 특정 AWS 리전에 연결된다. 버킷에 데이터를 저장할 때마다 해당 데이터는 선택한 리전의 여러 AWS 시설에 중복 저장된다.
Amazon S3 서비스는 2개의 AWS 시설에서 동시에 데이터가 손실되는 경우에도 데이터를 안정적으로 저장하도록 설계되었다. - Amazon S3는 데이터가 증가하더라도 버킷 뒤에서 스토리지를 자동으로 관리한다. 이를 통해 사용자는 즉시 시작하고 애플리케이션 요구에 따라 데이터 스토리지를 확장할 수 있다.
- 또한 Amazon S3는 많은 양의 요청을 처리할 수 있도록 확장된다.
- 스토리지 또는 처리량을 프로비저닝할 필요가 없으며 사용한 양에 대해서만 비용이 청구된다.
- Amazon S3는 AWS Management Console, AWS CLI 및 SDK를 사용하여 액세스할 수 있다.
- REST 엔드포인트를 통해 버킷 내 데이터에 직접 액세스할 수 있다.
- HTTP 또는 HTTPS 액세스를 지원한다.

위 그림의 URL 기반 액세스를 지원하려면 S3 버킷 이름이 전역적으로 고유하고 DNS를 준수해야 한다. 또한 객체 키는 URL에 안전한 문자를 사용해야 한다.
사실상 무제한의 데이터를 저장하고 어디서든 해당 데이터에 액세스할 수 있는 이러한 유연성 덕분에 Amazon S3 서비스는 광범위한 시나리오에 적합하다.
S3의 일반 사용 사례
1. 애플리케이션 자산 저장
- 모든 애플리케이션 데이터의 위치로서, S3버킷은 EC2 또는 기존 서버의 애플리케이션을 비롯하여 애플리케이션 인스턴스가 액세스할 수 있는 객체를 저장하기 위한 공유 위치를 제공한다.
- 이는 사용자 생성 미디어 파일, 서버 로그 또는 애플리케이션에서 공통 위치에 저장해야 하는 다른 파일에 유용할 수 있다.
- 또한 웹에서 직접 콘텐츠를 가져올 수 있기 때문에 애플리케이션이 해당 콘텐츠를 제공할 필요 없이 클라이언트가 Amazon S3에서 직접 데이터를 가져오도록 할 수 있다.
2. 정적 웹 호스팅
- S3 버킷은 HTML, CSS, JavaScript 및 기타 파일을 포함하여 웹 사이트의 정적 콘텐츠를 제공할 수 있다.
3. 백업 및 재해 복구
- Amazon S3는 뛰어난 내구성 덕분에 데이터 백업을 저장할 수 있다.
- 가용성 및 재해 복구 기능을 한층 강화하기 위해 Amazon S3는 한 리전의 S3 버킷에 들어있는 데이터를 다른 S3리전으로 자동 복제할 수 있는 교차 리전 복제를 지원하도록 구성할 수도 있다.
4. 빅 데이터를 위한 스테이징 영역
- Amazon S3의 확장 가능한 스토리지 및 성능 덕분에 다양한 빅 데이터 도구를 사용하여 분석하려는 데이터를 준비하거나 장기간 보관할 수 있다.
ex) Amazon S3의 DataStage는 Amazon RedShift로 로드되어 Amazon EMR에서 처리되거나 Amazon Athena와 같은 도구를 사용하여 쿼리될 수 있다. - 또한 Snowball과 같은 AWS Import/Export디바이스를 사용하여 대량의 볼륨을 Amazon S3로 가져오거나 내보낼 수 있다.
5. 그외 다수
- Amazon S3를 사용하여 데이터를 저장하고 액세스하는 것이 매우 간단하므로 AWS 서비스 및 애플리케이션의 다른 부분에 자주 사용되는 것을 쉽게 발견할 수 있다.
AWS에서 애플리케이션을 빌드할 때 Amazon S3가 어떻게 도움이 되는지 살펴볼 수 있다.
Amazon S3 시연

- 새 버킷을 생성한 다음 데이터를 추가하고, 이 데이터를 검색해보자

- 버킷 이름은 DNS를 준수해야 한다.
- 다음은 리전을 설정해야 한다. 이 경우에는 Amazon EC2 인스턴스에서 실행 중인 애플리케이션이 이 데이터에 액세스해야 하고 해당 EC2 인스턴스 세트가 서울리전에 있음을 알고 있으므로 리전을 서울로 설정한다.
- 해당 시점에서 버킷 생성에 필요한 모든 결정을 내렸다.
- 다른 설정기능들은 버킷의 버전 관리 또는 기본 권한 변경과 같은 것들이다.
권한 변경을 통해 버킷에 대한 액세스를 퍼블릭 인터넷 사용자 또는 특정 AWS 사용자에게 할당할 수 있다. - 여기서는 기본값을 사용하기 때문에 생성버튼을 눌러주면 된다.

이제 버킷이 생성된 것을 확인할 수 있고 이름은 amazing-bucket-55임을 확인할 수 있다.

- 버킷을 클릭하면 버킷이 비어 있다는 메시지가 표시되고 새 객체를 업로드할 수 있다.
- 또한 이 버킷에 대한 속성 정보도 볼 수 있다.

- 업로드 버튼을 클릭하여 Amazon Management Console에서 파일을 끌어다 놓고 파일에 대한 권한을 수정할 수 있다.
- 하지만 AWS CLI를 통하여 파일을 업로드 하는 것을 선호한다.
- AWS CLI 터미널 창을 열고 test파일을 나중에 EC2인스턴스에서 액세스할 수 있도록 S3 버킷에 복사해보자
asw s3 cp demo.txt s3://amazing-bucket-55/test.txt
위의 명령어를 사용하여 demo.txt를 S3 버킷에 복사할 수 있다.
aws s3 sync some-folder s3://amazing-bucket-55/files
- 로컬 시스템에 있는 폴더의 내용을 가져올 수도 있고 sync명령을 사용하여 해당 폴더를 동기화시킬 수도 있다.
그러면 AWS CLI가 각 파일을 처리하고 버킷에 있는지 확인한 다음, 버킷에 없는 경우 업로드한다. - 계속해서 EC2 인스턴스에 대해 SSH를 수행하고, 인스턴스가 계정의 모든 S3 버킷에 대한 읽기 액세스를 제공하는 IAM 역할로 프로비저닝되었는지 확인할 수 있다.
ssh -i ../secret/xxxx.pem ec2-user@ec2-35-163-224-121.us-west-2.compute.amazonaws.com
- 그러면 이 EC2 인스턴스에서 Amazon S3 amazing-bucket-55에 무엇이 있는지 확인해보겠다.
- S3 amazing-bucket-55에 aws s3 ls를 수행하고 이를 반복하여 모든 경로를 확인한다.
aws s3 ls s3://amazing-bucket-55 --recursive
- 파일이 3개가 있음을 확인할 수 있다.
- 전과 같이 copy명령을 수행할 수 있지만 지금은 반대로 버킷 이름부터 지정한다.
파일 다운로드
aws s3 cp s3://amazing-bucket-55/test.txt
- 버킷에서 test.txt파일을 복사했다.
- 계속해서 로컬 EC2 인스턴스 스로티지에서 ls를 수행하면 S3의 객체가 표시되는 것을 확인할 수 있다.
aws s3 sync s3://amaing-bucket-55/file folder
- 해당명령을 수행하면 EC2 인스턴스의 로컬 폴더로 동기화할 수 있다.
- 이제 해당 폴더를 다운로드 할 수 있고 해당 폴더에 2개의 파일이 있음을 확인할 수 있다.
이것으로 데이터를 저장하고 데이터를 백업하는 간단한 Amazon S3 시작하기를 살펴봤다.
Amazon Management Console로 돌아가 새로 고침을 하면 S3버킷에 새로운 파일이 추가된 것을 확인할 수 있다.
이들은 관리 콘솔 및 AWS CLI에서 본 것과 동일한 파일이다.
AWS Global Infra
- AWS 기반 IT 호스팅에 대한 모든 것, 그리고 AWS를 설정하는 방식이 왜 중요한지에 대한 얘기
- AWS 글로벌 인프라는 다음 세 가지 주제로 나눌 수 있다.
AWS 리전
AWS 가용영역
AWS 엣지 로케이션
Region
- 리전은 2개 이상의 가용 영역을 호스팅하는 지리적 영역이고, AWS 서비스에 대한 구성 수준이다.
- 리소스를 배포할 때 리소스가 위치하는 리전을 선택한다.
이때, 어느 리전이 비용을 최소화하고 규제 요구 사항을 준수하면서도 지연시간을 최적화하는 데 도움이 되는지 고려하는 것이 중요하다. - 비즈니스 요구 사항을 더 잘 충족하기 위해 여러 리전으로 리소스를 배포할 수도 있다.
ex) 개발자 리소스를 한 리전에 배포해야 하지만 기본 고객 기반이 다른 리전에 있는 경우 개발 자산을 한 리전에 배포하고 고객용 솔루션은 다른 리전에 배포할 수 있다.
ex) 또는 동일한 리소스를 여러 리전에 배포하여 고객의 위치와 상관없이 전 세계적으로 일관된 경험을 제공할 수 있다. - 최소의 비용으로 짧은 시간 내에 지연 시간을 최소화하고 조직의 민첩성을 향상시킬 수 있다.
- 리전은 서로 완전 분리된 개체이다. 한 리전의 리소스는 다른 리전으로 자동복제되지 않으며, 모든 서비스가 모든 리전에서 이용 가능한 것은 아니다.
물론 Amazon S3 또는 Amazon EC2와 같이 모든 리전에서 이용 가능한 서비스도 있다. - aws.amazon.com/about-aws/global-infrastructure해당 페이지에서 각 리전에서 사용 가능한 서비스를 확인할 수 있다.
Available Zone(가용 영역)
- 가용 영역은 특정 리전에 존재하는 데이터 센터들의 모음을 의미한다.
- 각 가용 영역은 물리적으로 서로 격리되어 있지만 빠르고 지연 시간이 짧은 네트워크로 서로 연결되어 있다.
- 각 가용 영역은 물리적으로 구분된 독립적인 인프라이다.
- 물리적은 물론 논리적으로 분리되어 있다.
- 자체적으로 개별 무정전 전원 공급 장치, 현장 예비 발전기, 냉각 장비 및 네트워크 및 연결 장치를 보유하고 있다.
- 독립적인 전력 회사의 망을 통해 전력이 공급되며, 여러 개의 티어 1 전송 서비스 공급업체를 통해 네트워크 연결된다.
- 가용 영역을 격리함으로써 다른 영역의 장애로부터 보호되고 특정 리전에서 고가용성 및 데이터 중복성이 보장된다.
그러므로 하나의 영역이 중단되더라도 다른 영역에서 요청을 처리할 수 있다. - 이것은 AWS가 여러 가용 영역에 데이터를 프로비저닝하는 것을 모범 사례로 추천하는 이유이기도 하다.
Edge Location(엣지 로케이션)
- AWS Edge Location은 Amazon CloudFront라고 하는 콘텐츠 전송 네트워크(CND)를 호스팅한다.
- CloudFront는 고객에게 콘텐츠를 전송하는 데 사용된다.
- 콘텐츠에 대한 요청이 자동으로 가장 가까운 엣지 로케이션으로 라우팅되므로 콘텐츠가 더욱 빨리 최종 사용자에게 전송된다.
- 엣지 로케이션의 글로벌 인프라를 사용하면 최종 고객이 더욱 빠르게 콘텐츠에 액세스할 수 있다.
- 일반적으로 엣지 로케이션은 가용 영역의 리전과 마찬가지로 인구 밀도가 높은 지역에 위치하기 때문이다.
'AWS Cloud Practitioner Essentials' 카테고리의 다른 글
| AWS Cloud Practitioner Essentials M3-1 (0) | 2021.02.24 |
|---|---|
| AWS Cloud Practitioner Essential M2-3 (0) | 2021.02.23 |
| AWS Cloud Practitioner Essential M2-1 (0) | 2021.02.23 |
| AWS Cloud Practitioner Essentials M1 (0) | 2021.02.22 |
| AWS Cloud Practitioner Essentials (0) | 2021.02.22 |